Tolino Epos - endlich Firmware Update (11.2.2)
2018-05-07
Es hat Ewigkeiten gedauert, bis der Tolino Epos endlich mal das tut, was man von einem eBook-Reader erwartet.
Meinen habe ich Ende November bekommen und so schön, groß, er auch ist, ein elementares Ding hat einfach nicht zuverlässig funktioniert. Das Umblättern, und wenn das keine elementare Funktion eines Lesegerätes ist, dann weiß ich auch nicht.
Manchmal hat ein Tippen oder Wischen gar kein Ergebnis zustande gebracht und manchmal ist er gleich zur übernächsten Seite gegangen. Absolut frustrierend und eine Frechheit!
Anfang März kam dann die Version 11.2 heraus, die wohl, Berichten zufolge, dieses Problem für den Epos auch behoben hat, aber mit einigen Vision Probleme verursacht hatte. Und was macht Tolino? Zieht das ganze Update für alle Geräte wieder zurück. Keine Chance als Epos Anwender daran zu kommen.
Aber dann heute, gibt es tatsächlich eine neue Version 11.2.2 und die scheint, ersten Versuchen zufolge, das Problem endlich behoben zu haben.
Python 3.x MacOS: SSL: CERTIFICATE_VERIFY_FAILED
2017-12-15
Nachdem ich mein Python 3.4 unter OS X High Sierra mit dem offiziellen Installer auf 3.6 aktualisert hatte liefen einige meiner Skripte nicht mehr die auf Internetressourcen zugreifen.
Und bei Befehlen wie diesem hier:
outp = urlopen('https://irgendwas.com/pfad')
kam der Fehler:
urllib.error.URLError: <urlopen error [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed (_ssl.c:777)>
Abhilfe hat das ausführen des mitgeliferten Komandos:
/Applications/Python 3.6/Install Certificates.command
geschafft.
Fujitsu ScanSnap OCR für beliebige PDF (El Capitan)
2015-11-28
Der hier beschriebene Weg um beliebige PDFs der, dem ScanSnap beigelegten, Abbyy Software vorzuwerfen, scheitert unter El Capitan an den Schwierigkeiten ein lauffähiges pdftk zu bekommen.
Eine Abhilfe besteht darin statt dessen die Coherent PDF Command Line Tools zu verwenden. Einfach herunterladen und die cpdf Datei z.B. unter /usr/local/bin speichern.
Dann die Zeile
/usr/local/bin/pdftk "$1" update_info ~/bin/lib/SnapScanPDFInfo.txt output "$tmpfile" 2> /dev/null
ersetzen durch
/usr/local/bin/cpdf -set-creator "ScanSnap Manager #S1100" "$1" -o "$tmpfile"
Und schon geht es auch auf dem neuesten MacOSX wieder und die Datei ~/bin/lib/SnapScanPDFInfo.txt kann man sich dann auch sparen.
Bye Mecurial, welcome git
2015-05-31
Das ist doch ein wahres Drama, mit den Versionsverwaltungssystemen.
Erst SVN, da altbekannt und von BBEdit unterstützt, und dann nach langem hin und her zwischen Mercurial und GIT zu ersterem gewechselt, da es mir einfach intuitiver vorkam. Tut es immer noch, im Vergleich zu git, aber dann kommt BBEdit in Version 11.1 mit eingebauter git-Unterstützung. So gut ich auch mit SourceTree zurechtgekommen bin, so praktisch finde ich doch, wenn alles im Editor der Wahl untergebracht ist, zumindest das was man täglich so braucht.
Heute habe ich ein Projekt mittels fast-export und dieser Anleitung konvertiert, und auf den ersten Blick sieht es durchaus so aus, als ob das auch geklappt hat.

Jetzt muß ich mich aber erstmal wieder mit der Philosophie von git vertraut machen, da ich aber nicht wirklich sooo viele Features nutze, sollte sich der Aufwand in Grenzen halten. Die BBEdit-Integration scheint auf jeden Fall zu halten was sie verspricht, jetzt muß ich mir nur noch ein paar Tastaturkürzel dafür überlegen.
Bye Subversion, hello Mercurial
2014-03-14
Da bin ich jetzt extra TextWrangler auf BBedit umgestiegen, unter anderem wg. der Subversion Unterstützung, und jetzt verlasse ich Subversion und sattle um auf Mercurial.
Warum? Vermutlich einfach aus Neugierde auf Neues. Subversion hat mir immer treue Dienste geleistet und hat für das, was ich so damit mache, immer ausgereicht (das war bei mir aber auch bei RCS und CVS nicht anders). Trotzdem habe ich mir mal ein paar neue Sachen angeschaut. Bazaar hat mich gleich abgeschreckt, insbesondere der mitgelieferte Explorer und die dauernden Fehler die ich mir auf die Schnelle nicht erklären konnte. Git ist sicher nicht das Dümmste, aber auch da bin ich in Laufe meiner Tests auf Verhalten gestoßen die ich mir intuitiv nicht erklären konnte; aber immerhin haben mich meine git-Experimente auf die Spur von SourceTree gebracht, was mich wiederum in Richtung Mercurial gestoßen hat. Das zusammen mit hgflow und SourceTree konnte mich wirklich überzeugen. Alle läuft so wie ich es mir vorstelle.
Meine alten Sachen habe ich aber nicht konvertiert, sondern habe mir einfach die relevantesten Stände ausgecheckt und der Reihe nach in Mercurial wieder commit-ed.
Mit dem Umstieg auf BBEdit bin ich aber trotzdem noch sehr zufrieden. Mit Projekten, Clippings und der integrierten Vorschau bietet er doch einiges mehr als TextWrangler und für mich auch mehr Relevantes als seinerzeit Textmate. Nach vielen, vielen Jahren fühle ich jetzt wieder die Editor-Macht wie früher beim XEmacs, den ich seinerzeit beim Umstieg von Linux auf dem Mac aus irgendwelchen Gründen1 zurück gelassen habe. Nur dem Gnus weine ich als Newsreader und Mailclient noch immer hinterher.
-
Ok, der Grund war, daß sich meine
.emacsnicht ohne weiteres hat übernehmen lassen und Textmate seinerzeit ein akzeptabler Nachfolger war, so daß ich das nicht weiter verfolgt habe. ↩
Schon wieder ein neuer Editor: BBEdit
2014-03-09
Tja, schon wieder mal ein neuer Editor. Nach meinem Umstieg von Textmate auf TextWrangler habe ich jetzt das Upgrade von zweiterem auf seinen großen Bruder BBEdit gemacht.
Gereizt daran hat mich hauptsächlich die Unterstützung von Subversion und die Textclippings. Mit den Clippings habe ich noch keine weiteren Erfahrungen gesammelt, aber die Integration einer Versionsverwaltung ist schon was wert. Dank der engen Verwandschaft zwischen TextWrangler und BBEdit war der Umstieg eine Sache von Minuten. Meine Text-Filter und meine bevorzugten Farbeinstellungen konnte ich einfach kopieren, das Verhalten ist im Wesentlichen identisch und ich musste nur ein paar Einstellungen nachziehen und ein paar Tastaturkürzel neu definieren.
Ein kurzer Zwischentest mit Sublime Text hat mich nicht vom Hocker gehaut, auch wenn die automatische Hervorhebung beim Suchen (und Ersetzen, auch von Regular Expression) da eine feine Sache ist.
Keyboard Maestro, Pathfinder und ImageOptim
2014-02-23
ImageOptim macht einen prima Job beim Verkleinern von Bilddateien, und das ohne merkbaren Verlust an Qualität. Als neuer Benutzer von Keyboard Maestro liegt es da natürlich nahe, den Prozess des “Bildverkleinerns” zu optimieren. (Der Screenshot (PNG) in diesem Artikel hat z.B. ca. 160kB, nach der Anwendung von ImageOptim nur noch 55kB.)
Da ich aber Path Finder statt des Finders einsetze helfen die zahlreichen Beispiele für solcherlei Sachen nicht viel weiter.
Eine Variante um das Ganze zu umgehen, ist es vor den Aktionen die die Auswahl des Finders durchnudeln, eine Aktion einzubauen die aus PathFinder heraus “Ablage > Im Finder anzeigen” aufruft. Dabei gerät man allerdings in Bekanntschaft mit Timingproblemen und ruft extra ein Programm aus, mit dem man eigentlich ansonsten nicht zu tun hat.
Als Abhilfe können hier ein paar Zeilen AppleScript dienen die dieselbe Funktionalität bereitstellen.

Bei mir liegt ImageOptim unter /Applications/Utils, der Pfad ist also ggf. anzupassen falls es woanders liegt.
Keyboard Maestro als Textexpander Ersatz
2014-02-19
Zur Zeit versuche ich meine Tools auf das Nötigste einzuschränken. Im Rahmen dessen ist unter anderem TextExpander (auf dem Mac) über die Klippe gesprungen. Für die paar Sachen die ich damit mache ist es vermutlich Overkill.
Zudem hat mich am Textexpander gestört, daß es mir in einer virtuellen Maschine, sei es Parallels oder Fusion nichts gebracht hat. Wohingegen ich Kürzel die ich in Keyboard Maestro mit z.B. “Insert text by typing” vereinbart habe durchaus funktionieren.
So kann ich ein Kürzel, das ich durchaus mehr als nur 10x am Tag benutze, welches mir das aktuelle Datum im ISO-Format einfügt, auch in einer virtuellen Maschine einfach durch Eingabe von +ds aufrufen:

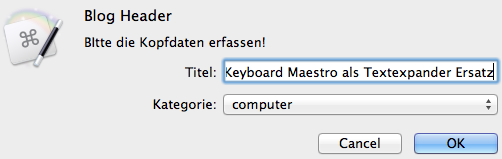
Zwar hat es eine etwas längere Lernkurve (nur minimal) aber man kann, ebenso wie in Textexpander, auch anspruchsvollere Sachen inkl. Benutzerinteraktion damit erstellen:

Die obige Aktion erfragt einen Titel und einen Kategorie aus einer Auswahl und fügt mir die entsprechenden Eingaben dann in meine Vorlage für den Kopf eines Statamic Beitrages ein.
Was mir nicht so gut gefällt, ist, daß man wohl die Clipboard Historie nicht ganz ausschalten kann (nur das auf Festplatte speichern), aber da mir, zumindest bis jetzt, noch keine ähnlich negativen Sachen aufgefallen sind wie seinerzeit als ich die Historie in Launchbar aktiviert hatte, nämlich sehr behäbiges Einfügen von großen Bilddaten, hat sie ja auch etwas praktisches, zumal Sachen die wie ein Passwort aussehen zum einen in der Anzeige der Historie ausge-x-t werden und zum anderen wenn sie an der 10. Position angekommen sind, gelöscht werden.
Neben Textexpander hat mir Keyboard Maestro auch jegliche Tools zum gezielten Platzieren von Fenstern ersetzt:

(s.a. iEnno: Fenster organisieren mit Keyboard Maestro)
Mein Arsenal an unverzichtbarem besteht also zur Zeit aus Launchbar, Hazel, Keyboard Maestro und 1Password.
Nachtrag: Man kann die Anzahl der gespeicherten Clipboards via Kommandozeile beinflussen:
defaults write com.stairways.keyboardmaestro.engine MaxClipboardHistory -int 12
defaults write com.stairways.keyboardmaestro.engine MaxConcealedPosition -int 3
So werden nur noch 12 Zwischenablagen aufbewahrt und Sachen die wie Passwörter aussehen bereits ab Position 4 gelöscht.
Fujitsu ScanSnap OCR für beliebige PDF
2014-01-14
So ein Fujitsu ScanSnap ist eine feine Sache. Mein ScanSnap S1100 leistet mir seit einiger Zeit treue Dienste beim Digitalisieren von Papierunterlagen. Was mir mit anderen Scannern nie gelungen ist, damit hat es geklappt. Alle Papierrechnungen, Rentenunterlagen, Verdienstbescheinigungen, Zeugnisse, etc. die sich so angesammelt haben sind digitalisiert und alles was neu anfällt wird auch gleich gescannt, in DevonThink Pro abgelegt und dem Altpapier übergeben.
Warum das geklappt hat ist die gute s/w-Bildverarbeitung des Scanners und der beiliegenden Software, das einfachere Handling des Einzugsscanners im Vergleich zu einem Flachbettscanner, meine Hazel-Workflows und das integrierte Abbyy OCR Modul.
Und um letzteres soll es hier gehen.
Die Abbyy Software arbeitet sehr gut beim Hinterlegen der gescannten Grafikdaten mit, per OCR gewonnener, Textinformationen. Dies funktioniert standardmäßig aber nur mit PDFs die auch vom ScanSnap generiert wurden und eben nicht mit beliebigen PDF; seien es Altdaten oder Scans die vom iPhone kommen. Das hier beschriebene Verfahren mit tesseract eignet sich gut um ASCII-Dateien aus den Scans zu generieren, aber weniger dafür die PDFs mit — durchsuchbarem — Text zu ergänzen.
Was liegt also näher als zu versuchen die vorhandene — Fujitsu gebundelte — Software von Abbyy auch auf diese Dateien loszulassen.
Eine Analyse der vom ScanSnap erzeugten Dateien hat ans Tageslicht gebracht, daß diese im Feld Creator ScanSnap Manager #S1100 und im Feld Producer Mac OS X 10.8.4 Quartz PDFContext stehen haben. Nur wie bekommt man das jetzt am geschicktesten in die Dateien hinein?
Erfreulicherweise gibt es pdftk, welches sich über die MacPorts auch bequem auf dem Mac installieren lässt.
Fehlt also nur noch ein Skript das einem die Hauptarbeit abnimmt.
pdfocr.sh:
#!/bin/bash
## testen ob Parameter 1 als Datei exitsiert
if [ ! -f "$1" ]
then
echo "$1: File does not exist"; exit 1
fi
base=$(basename -s .pdf "$1")
## TMP-Verzeichnis anlegen und darin Datei definieren
tmpdir=$(mktemp -d -t pdfocr)
if [ $? -ne 0 ]; then
echo "$0: Can't create temp dir, exiting..."; exit 1
fi
tmpfile="${tmpdir}/${base}.pdf"
/usr/local/bin/pdftk "$1" update_info ~/bin/lib/SnapScanPDFInfo.txt output "$tmpfile" 2> /dev/null
open -a 'Scan to Searchable PDF.app' "$tmpfile"
~/bin/lib/SnapScanPDFInfo.txt:
InfoKey: Creator
InfoValue: ScanSnap Manager #S1100
InfoKey: Producer
InfoValue: Mac OS X 10.8.4 Quartz PDFContext
2015-11-28: Unter Mac OS 10.11 (El Capitan) scheitert die Sache an einem renitenten pdftk; eine Abhilfe habe ich hier beschrieben.
Blick vom Kornberg zum Schneeberg
2014-01-12
Mal was hübsch kitschiges von einem schneelosen Winter im Fichtelgebirge:

Kamera: Pentax K-5
Objektiv: Pentax Pentax SMC-DA 35mm
ISO: 100
Blende: 19
Belichtungszeit:1/500s -- 1/2s (HDR aus 5 Bildern)